7.1.2 Структура
Cypher использует подход SQL-запросов, составленных из различных предложений. Предложения связаны и передают промежуточные результирующие наборы друг другу. Например, соответствующие идентификаторы из одного предложения MATCH будут контекстом, в котором существует следующее предложение.
Язык запросов составляется из нескольких различных предложений. С деталями вы можете познакомиться далее в этом руководстве.
Вот некоторые из этих предложений, используемых для чтения из графа:
- MATCH: Образец (паттерн), которому соответствует граф. Это наиболее общий способ получения данных из графа.
- WHERE: Не вполне самостоятельное предложение, скорее, часть предложений MATCH, OPTIONAL MATCH и WITH. Добавляет ограничения в паттерн или фильтрует промежуточный результат на выходе предложения WITH.
- RETURN: Что должно быть получено на выходе.
Давайте проверим MATCH и RETURN в действии.
Представим себе в качестве примера следующий граф:
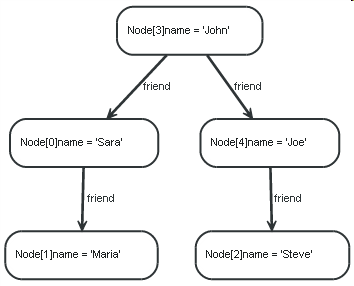
Рис. 7.1 Пример графа
Вот запрос, который находит пользователя с именем Джон (John) и его непрямых друзей (т.е. друзей его друзей) и возвращает как Джона, так и всякого найденного друга его друзей.
MATCH (john {name: 'John'})-[:friend]->()-[:friend]->(fof)
RETURN john, fof
Результат:
| john | fof |
|---|---|
| Node[3]{name:"John"} | Node[1]{name:"Maria"} |
| Node[3]{name:"John"} | Node[2]{name:"Steve"} |
Далее мы добавим фильтрацию, чтобы задействовать больше структурных элементов запроса.
Возьмём список имен пользователей и найдём все узлы с именами из этого списка, поставим им в соответствие друзей и вернём только тех из них, кто имеет свойство name, начинающееся на S.
MATCH (user)-[:friend]->(follower) WHERE user.name IN ['Joe', 'John', 'Sara', 'Maria', 'Steve'] AND follower.name =~ 'S.*' RETURN user, follower.name
| user | follower.name |
|---|---|
| Node[3]{name:"John"} | "Sara" |
| Node[4]{name:"Joe"} | "Steve" |
А теперь приведём примеры предложений, которые используются для обновления графа:
- CREATE (и DELETE): Создает (и удаляет) узлы и связи.
- SET (и REMOVE): Устанавливает значение свойства и добавляет метки узлам с помощью SET; использует REMOVE для их удаления.
- MERGE: Сопоставляет существующие или создает новые узлы и паттерны. Особенно полезно в сочетании с ограничениями уникальности.
Примеры использования Cypher вы можете найти в Главе 5 «Примеры моделирования данных», а также в остальной части этой главы, посвященной деталям языка Cypher. Чтобы использовать Cypher из Java, обратитесь к Разделу 32.12 “Выполнение запросов Cypher из Java”.