10.5 Агрегация
- 10.5.1 Введение
- 10.5.2 COUNT
- 10.5.3 Статистика
- 10.5.4 COLLECT
- 10.5.5 DISTINCT
10.5.1 Введение
Для вычисления агрегированных данных Cypher предлагает агрегацию во многом похожую на GROUP BY в SQL.
Агрегатные функции принимают на входе множество значений и вычисляют по ним агрегатное значение. Примерами служат avg, которая вычисляет среднее множества числовых значений, или min, которая находит наименьшее числовое значение в наборе.
Агрегация может быть выполнена по всем сопоставимым подграфам, или же может быть выполнено дальнейшее разбиение по вводимым ключевым значениям. Это - неагрегатные выражения, которые используются для группировки значений на входе агрегатных функций.
Итак, если оператор возврата результата выглядит примерно так:
RETURN n, count(*)
Мы получим два выражения на выходе - n и count(*). Первое – n – не является агрегатной функцией и, следовательно, оно будет служить ключом группировки. Последнее count(*) – является агрегатным выражением. Поэтому сопоставимые подграфы будут подразделяться на различные кусты, в зависимости от ключа группировки. Затем агрегатная функция будет выполняться на этих кустах, вычисляя агрегатные значения.
Если вы хотите использовать агрегаты для сортировки вашего результирующего набора, агрегация должна быть включена в RETURN, чтобы использоваться в ORDER BY.
Последний кусок головоломки – ключевое слово DISTINCT. Оно используется, чтобы сделать все значения уникальными, прежде чем пропустить их через агрегатную функцию.
Здесь полезным будет пример. В нём мы выполняем запрос на следующих данных:
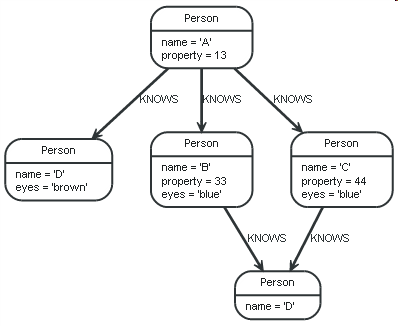
Запрос
MATCH (me:Person)-->(friend:Person)-->(friend_of_friend:Person) WHERE me.name = 'A' RETURN count(DISTINCT friend_of_friend), count(friend_of_friend)
В этом примере мы пытаемся найти всех друзей наших друзей и пересчитать их. Первая агрегатная функция, count(DISTINCT friend_of_friend), учтёт friend_of_friend только раз — DISTINCT устранит дубликаты. Последняя агрегатная функция, count(friend_of_friend), сможет обнаружить того же friend_of_friend неоднократно. В этом случае, оба B и C знают D, в результате чего D будет учтен дважды при отсутствии DISTINCT.
Таблица 10.46 Результат
| count(distinct friend_of_friend) | count(friend_of_friend) |
|---|---|
| 1 | 2 |